博主提交的PR已合并,更新FunASR到最新版即可
太长不看,直接解决问题(覆盖安装博主Fork并打补丁的FunASR库):pip install --no-cache-dir git+https://github.com/MotorBottle/FunASR.git@main
已提交PR,该PR尚未合并,但测试有效,合并后会在此说明,如已合并,直接pip升级至最新版FunASR库即可
FunASR 长音频GPU推理降速问题(根本原因:AutoModel 在初始时把所有运行配置放在同一个全局 kwargs 字典里,多模型推理时,这个字典会被内部逻辑实时修改,例如调整 batch_size、ncpu 等参数,推理结束后不会恢复原值)
观察现象
- 处理 30 分钟以上音频时,发现第一次推理速度很快,但同一段音频第二次推理耗时几乎翻倍甚至更长。
- GPU 始终运行在
cuda:0说明不是推理设备问题,但性能劣化会一直持续,除非重启进程。
根本原因
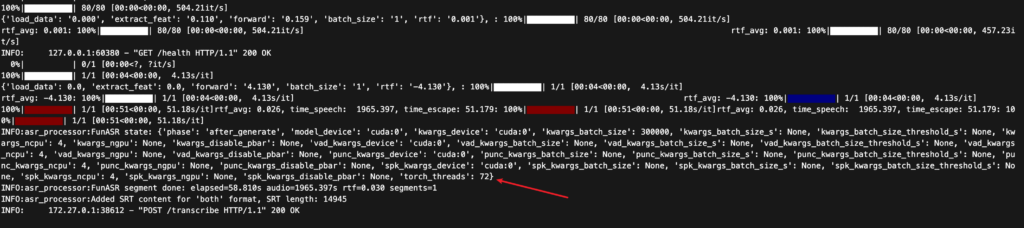
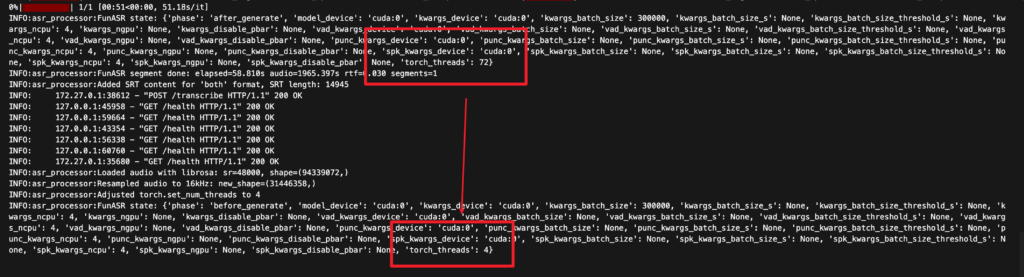
- FunASR 的
AutoModel将运行时配置(kwargs、vad_kwargs、punc_kwargs、spk_kwargs等)保存为可变字典。 - 长音频推理过程中,这些字典会被修改(例如
ncpu默认是 4, 但同时运行的内部逻辑修改torch_threads,推理结束后torch_threads变为72)。由于 FunASR 不会恢复默认配置,下一次请求就会沿用污染过的状态,导致速度下降。

解决方案
- 在
AutoModel构建完所有模块后,立即对每个*_kwargs做快照,并在每次推理前恢复这份基准配置(包括 VAD、标点、说话人识别模块)。 - 重新写入期望的参数如
ncpu,仅在线程设置发生变化时调用torch.set_num_threads(),防止线程数漂移。 - 效果:长音频可多次连续推理而不会污染默认参数,性能恢复稳定。
P.S. 目前只发现torch_threads遭到意外更改,如果需要最小变更,只针对它做修复也是可行的
