在使用Ollama进行API请求时,了解并正确设置上下文参数是至关重要的,尤其是当你需要处理长文本时。不同于一些常见的模型,Ollama的默认上下文窗口较小,例如llama3.1 70b模型默认仅有1k的上下文,其他很多模型也只有默认2k上下文。如果不加调整,在处理较长文本时,可能会遇到上下文溢出或者处理效率低下的问题。因此,在API请求中通过options带上num_ctx参数来扩大上下文窗口是非常重要的一步。
Ollama上下文设定
默认情况下,Ollama的上下文窗口大小设置得相对保守,以保持整体性能和资源的合理分配。例如,常见的设置是2k上下文窗口,但对于一些最新的模型如llama3.1 70b,默认仅为1k。这意味着如果你需要处理超过1k的输入内容,你必须手动调整num_ctx参数。例如:
{
"options": {
"num_ctx": 8192
}
}通过这种方式,你可以根据需求将上下文窗口设置得更大,以便模型能够处理更长的文本。模型所能支持的最大上下文通常会在Ollama的Library中模型介绍页面标出。如果没有写通常是8K,例如Gemma2和llama3都是8k,而LLama3.1和qwen2的部分版本则都支持到了128k。
GPU显存与上下文窗口大小的关系
你的硬件配置对于设定上下文窗口大小至关重要。以我的配置为例:两张2080ti和一张P4,总共52GB显存。在这种配置下,我能够将Ollama的qwem2:72b模型(默认q4_0量化)上下文窗口开到11k(最多11600)。如果要进一步将上下文窗口扩大到128k,全开的话,显存需求会暴增至约82GB左右,基本上需要一台4卡服务器才能支持。
2025更新:
注意到很多量化的模型最大上下文都从官方号称的超过128k限制到了32k左右,如有更大需求可能需要对配置做一些修改
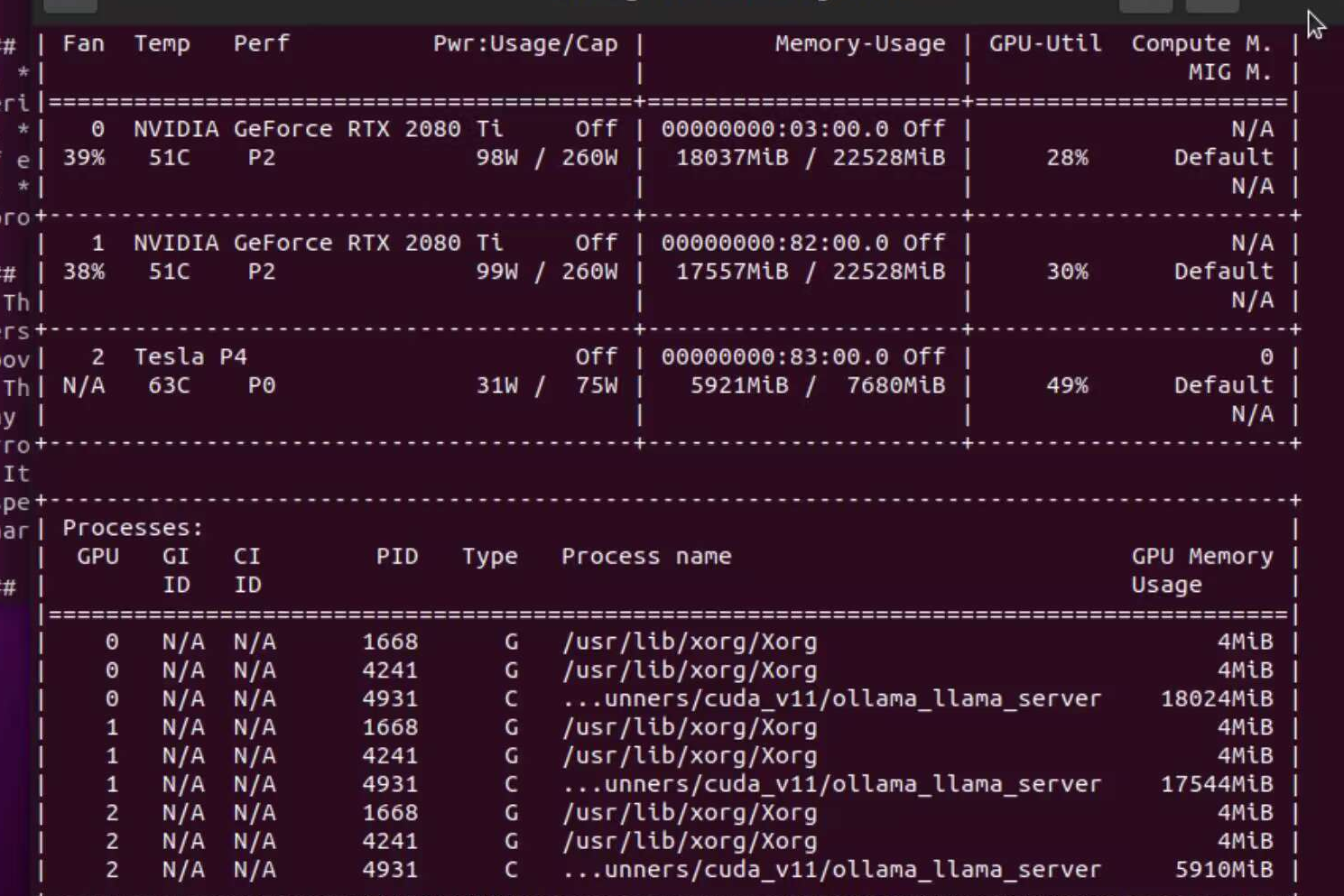
虽然128k上下文窗口的设定可以极大地增强模型在长文本处理上的能力,但对显存的需求也非常苛刻。因此,在显存不充裕的情况下,11k的上下文窗口已算是勉强可用,出字速度和响应时间也都在合理范围内。
监控显存占用情况
在API请求中设置了上下文大小后,你可以通过ollama ps指令在host主机上查看显存的实际占用情况。该命令可以帮助你实时监控模型在运行时的显存使用,并根据需要进行调整。例如,在你设置了一个较大的上下文窗口后,通过ollama ps可以检查是否有足够的显存余量,确保模型能够平稳运行。
ollama ps通过这种方式,你能够动态了解显存使用情况,及时调整上下文大小或者进行其他优化,避免因显存不足导致的模型崩溃或性能下降。

显存充足的情况下,PROCESSOR会显示100%gpu。
如果显示CPU+GPU,则说明超出了显存的可用范围。
经过我的测试,当由于大上下文窗口造成Ollama切换至非纯GPU模式下时,模型不仅会出现性能的下降,有时还会出现回复乱码、幻觉严重等问题,因此请尽量保证模型运行在纯GPU模式下。
上下文设定的实用建议
- 根据硬件配置合理设置:首先,根据你当前的硬件配置,合理设定上下文窗口大小。以52GB显存为例,11k的上下文窗口既能保证较好的文本处理能力,又不会导致显存不足。
- 测试并优化设置:对于一些特定的任务,尝试不同的上下文窗口大小,观察模型的表现和显存使用情况。找出一个在性能和资源利用之间的最佳平衡点。
- 注意模型的默认设置:在使用新模型时,注意它们的默认上下文窗口设置,并根据任务需求调整。尤其是在处理长文本时,手动扩大上下文窗口是必要的。
通过对Ollama上下文参数的深入理解和合理设置,你可以在现有硬件配置下,最大化模型的性能并高效处理各种文本任务。

帮大忙了,感谢大佬!
客气